数据类型(7)
- 原始数据类型(6种)
a. 数值
b. 字符串
c. 布尔值
d. undefined
e. Null
f. Symbol(ECMAScript 6 新增)
g.任意精度的整数 (BigInt) ,可以安全地存储和操作大整数,甚至可以超过数字的安全整数限制
- 引用数据类型
a. 对象
b. 数组
c. 函数
…
运算符
加减乘除、取模、自增自减
| var a = 1;
var b;
var sum = (b = a++ + --a) + a-- + b++;
|
数组
创建数组
1
2
3
4
5
| var arr = [1,2,3]
var arr = new Array()
var arr = new Array(9)
var arr = new Array('first', 'second', 'name')
|
数组方法
concat: 连接两个或多个数组,并返回一个新数组。
join: 将数组中的所有项连接成一个字符串。
pop: 删除并返回数组的最后一项。
push: 在数组的末尾添加一个或多项并返回数组的新长度。
shift: 删除并返回数组的第一项。
unshift: 在数组的开头添加一个或多项。
slice: 返回一个数组的片段,该片段包括开始索引到结束索引(不包括结束索引)的所有项。
splice: 在数组中插入、删除或替换项。
sort: 对数组的所有项进行排序。
reverse: 反转数组中的项的顺序。
indexOf: 返回数组中第一个与给定值匹配的项的索引,如果未找到,则返回 -1。
lastIndexOf: 返回数组中最后一个与给定值匹配的项的索引,如果未找到,则返回 -1。
forEach: 对数组中的每一项执行给定的回调函数。
map: 对数组中的每一项执行给定的回调函数,并返回一个新数组,其中的每一项是回调函数的返回值。
filter: 对数组中的每一项执行给定的回调函数,并返回一个新数组,其中只包含回调函数返回 true 的项。
reduce: 从左到右对数组中的所有项进行累加,并返回单个值。
reduceRight: 从右到左对数组中的所有项进行累加,并返回单个值。
some: 如果数组中至少有一个项通过了给定的测试,则返回 true,否则返回 false。
every: 如果数组中的所有项都通过了给定的测试,则返回 true,否则返回 false。
JS编译原理
JavaScript 是一种解释型语言,而非编译型语言。这意味着,JavaScript 代码在运行时被动态解释,而不是在编译时预先翻译成机器代码。
在 JavaScript 中,代码会被加载到浏览器或 Node.js 环境中,然后通过 JavaScript 引擎(例如 V8)解释和执行代码。在解释代码之前,JavaScript 引擎会对代码进行词法分析和语法分析,以确定代码的语法正确性和语义。然后,代码将被执行。
总的来说,JavaScript 没有明确的编译过程,但它在加载和运行代码之前经过了词法和语法分析。
词法分析
词法分析的目的是将 JavaScript 代码的字符串形式转换为一系列词法单元 (tokens),每个词法单元代表 JavaScript 代码的一个有意义的组成部分,如变量名,运算符,函数等。
语法分析
语法分析的目的是将词法单元组合成语法树,语法树代表 JavaScript 代码的结构和语义。
闭包
产生条件
函数内部有另一个函数
函数内部的函数里面用到了外部函数的局部变量
外部函数将内部函数作为返回值 return 出去了。
好处:
闭包中的变量,充当全局变量使用,减少全局变量的混乱程度。
清除:
将变量设置为 null 即可。
new关键字
当我们在代码中使用 new 关键字,它会执行以下操作:
- 创建一个空对象
- 将该对象的原型链指向构造函数的原型对象
- 将函数内部的 this 关键字指向新创建的对象
- 在新创建的对象上执行构造函数中的代码
- 返回该对象
this
普通函数中,谁调用此函数,this 就指向谁。箭头函数中没有自己的this,在哪里定义,或者说箭头函数外部的this指向谁,就是谁。
方法中的this,指向调用方法的对象。
指向全局对象:全局函数中的this
事件中的 this,指向 dom 对象。
构造函数中的 this,指向 new 创建的对象。
call、apply、bind
它们的作用都是为了改变 this 的指向
区别是参数不同,第一个参数是想要使用的对象,第二个参数是传递给函数的参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| const dog = {
name: 'is dog',
sayName(name1, name2, name3) {
console.log(this.name)
}
}
const cat = {
name: '喵喵喵'
}
dog.sayName.call(cat, 1, 2, 3)
dog.sayName.apply(cat, [1, 2, 3])
const fn = dog.sayName.bind(cat, 1, 2, 3)
fn()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| const cat = {
name: '喵喵喵',
sayName() {
setTimeout(function() {
console.log(this)
})
}
}
const cat = {
name: '喵喵喵',
sayName() {
setTimeout(() => {
console.log(this)
console.log(this.name)
})
}
}
cat.sayName()
|
同步代码执行完毕,执行 nextTick,然后是异步代码(setTimeout),最后执行 setImmediate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| setImmediate(() => {
console.log('setImmediate')
})
process.nextTick(() => {
console.log(1)
})
console.log(2)
setTimeout(() => {
console.log(3)
}, 0);
|
setImmediate表示当前事件循环即将结束时,执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| setImmediate(() => {
console.log('setImmediate')
})
process.nextTick(() => {
console.log(1)
})
console.log(2)
setTimeout(() => {
console.log(3)
}, 0);
setTimeout(() => {
console.log(4)
}, 1000);
setTimeout(() => {
console.log(5)
}, 0);
console.log(6)
|
宏任务&微任务
宏任务:计时器、ajax、读取文件
微任务:promise.then
一次事件循环的执行顺序:
同步程序
process.nextTick
微任务
宏任务
setImmediate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
setImmediate(() => {
console.log('setImmediate')
})
process.nextTick(() => {
console.log(1)
})
console.log(2)
new Promise(r => {
console.log(7)
r()
}).then(() => {
console.log(8)
})
setTimeout(() => {
console.log(3)
}, 0);
setTimeout(() => {
console.log(4)
}, 1000);
setTimeout(() => {
console.log(5)
}, 0);
console.log(6)
|
浅拷贝、深拷贝
浅拷贝
1
2
3
4
5
6
7
8
9
10
11
12
13
| const obj = {
name: 'is obj',
girlfriend: {
name: '小红'
}
}
const o = Object.assign({}, obj)
obj.name = 'is o'
obj.girlfriend.name = '小花'
console.log(o)
|
深拷贝
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| const obj = {
name: 'is obj',
girlfriend: {
name: '小红'
}
}
function deepClone(obj) {
if (typeof obj !== 'object' || obj === null) {
return obj;
}
const clone = Array.isArray(obj) ? [] : {};
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
clone[key] = deepClone(obj[key]);
}
}
return clone;
}
|
JSON.stringify实现深克隆
将一个 JSON 对象,转化为字符串,通过 JSON.parse 将字符串转化为对象,从而实现深克隆
1
2
3
4
5
6
7
8
9
10
| const obj = {
name: 'is obj',
girlfriend: {
name: '小红'
}
}
const o = JSON.parse(JSON.stringify(obj))
console.log(o)
|
JSON.stringify 存在的两个问题:
- 无法拷贝函数、正则表达式、特殊类型的对象(如Date对象)等。
- 对象中存在循环引用时会导致报错。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
const o = {
fn: function (params) {
console.log('is fn')
},
reg: /\.js$/ig,
date: new Date(),
n: null,
u: undefined,
name: 'hello alexCc',
s: new Set([1,1,2,2,3,3]),
m: new Map()
}
|
structuredClone 实现深克隆
structuredClone是浏览器提供的一种机制,用于在不同的上下文(例如Web Workers之间)传输和复制可结构化的数据。它是一种用于序列化和反序列化JavaScript对象的算法。
需要注意的是,structuredClone算法是浏览器提供的特性,它并不是JavaScript语言本身的一部分,因此在非浏览器环境中(例如Node.js),无法直接使用structuredClone。
对比 JSON.parse 需要注意的两个问题:
- 对象中存在方法,使用 structuredClone 拷贝会报错,而 JSON.parse 会丢失
- structuredClone 支持对象循环引用,JSON.parse 处理循环引用的对象会报错
1
2
3
4
5
6
7
8
9
10
11
12
| const o = {
reg: /\.js$/ig,
date: new Date(),
n: null,
u: undefined,
name: 'hello alexCc',
s: new Set([1,1,2,2,3,3]),
m: new Map()
}
|
parseInt
parseInt(string, radix) 解析一个字符串并返回指定基数的十进制整数,radix 是 2-36 之间的整数,表示被解析字符串的基数。
string: 要被解析的值。
- 如果参数不是一个字符串,则将其转换为字符串 (使用 ToString抽象操作)。
- 字符串开头的空白符将会被忽略。
parseInt (0.0000005) === 5 为 true
1
2
3
4
5
6
7
| (0.5).toString();
(0.05).toString();
(0.005).toString();
(0.0005).toString();
(0.00005).toString();
(0.000005).toString();
(0.0000005).toString();
|
- 可以发现当数字过小时,toString 输出的结果是科学计数法形式。
- parseInt 只能将字符串的前导部分解释为整数值;它忽略任何不能被解释为整数的代码单元,并且不会有忽略指示。
1
2
3
| parseInt(0.5)
parseInt(0.0000005)
|
radix 默认值是 10 吗,何种情况返回值是 NaN?
- 当 radix 值为 undefined、0 或未指定的,那 JavaScript 会如何处理这种情况:
- 如果输入的 string 以 0x 或 0X 开头,那么 radix 会被假定为 16 ,字符串的其他部分按照十六进制来解析。
- 如果输入的 string 以 0 开头,ES5 规定使用十进制,但并非所有的浏览器都支持,因此使用 parseInt 时,需要指定 radix
- 如果输入的 string 以其他任何值开头,radix 值为 10
- radix 参数的值为 2 ~ 36,当 radix 小于 2 或 大于 36(不包含 0),返回值为 NaN
1
2
3
| parseInt("123", 1);
parseInt("123", 38);
parseInt("123", -1);
|
- 待转换字符串中,所有的可转换数字都不小于 radix 值
例如 radix 值为 2 (二进制),而待转换字符串为 ‘3456’,二进制内只有 0、1 是基本算符,因此字符串 ‘3456’ 无法转换成二进制,返回值为 NaN。
1
2
| parseInt("3456", 2);
parseInt("45px", 3);
|
[‘1’, ‘2’, ‘3’].map(parseInt)
[parseInt(“1”, 0), parseInt(“2”, 1), parseInt(“3”, 2)]
parseInt(“1”, 0)
radix 为 0,且 string 以字符 1 开始,radix 值为 10,值为 1。
parseInt(“2”, 1)
符合 2.2 ,radix 小于 2,返回 NaN
parseInt(“3”, 2)
待转换字符串中,所有的可转换数字大于 radix 值,返回 NaN
渲染进程
GUI渲染线程
- 负责渲染页面,布局和绘制
- 页面需要重绘和回流时,该线程就会执行
- 与js引擎线程互斥,防止渲染结果不可预期
JS引擎线程
- 负责处理解析和执行javascript脚本程序
- 只有一个JS引擎线程(单线程)
- 与GUI渲染线程互斥,防止渲染结果不可预期
事件触发线程
- 用来控制事件循环(鼠标点击、setTimeout、ajax等)
- 当事件满足触发条件时,将事件放入到JS引擎所在的执行队列中
定时触发器线程
- setInterval与setTimeout所在的线程
- 定时任务并不是由JS引擎计时的,是由定时触发线程来计时的
- 计时完毕后,通知事件触发线程
- 异步http请求线程
- 浏览器有一个单独的线程用于处理AJAX请求
- 当请求完成时,若有回调函数,通知事件触发线程
为什么 javascript 是单线程的?
首先是历史原因,在创建 javascript 这门语言时,多进程多线程的架构并不流行,硬件支持并不好。
其次是因为多线程的复杂性,多线程操作需要加锁,编码的复杂性会增高。
而且,如果同时操作 DOM ,在多线程不加锁的情况下,最终会导致 DOM 渲染的结果不可预期。
为什么 GUI 渲染线程与 JS 引擎线程互斥?
这是由于 JS 是可以操作 DOM 的,如果同时修改元素属性并同时渲染界面(即 JS线程和UI线程同时运行),
那么渲染线程前后获得的元素就可能不一致了。
因此,为了防止渲染出现不可预期的结果,浏览器设定 GUI渲染线程和JS引擎线程为互斥关系,
当JS引擎线程执行时GUI渲染线程会被挂起,GUI更新则会被保存在一个队列中等待JS引擎线程空闲时立即被执行。
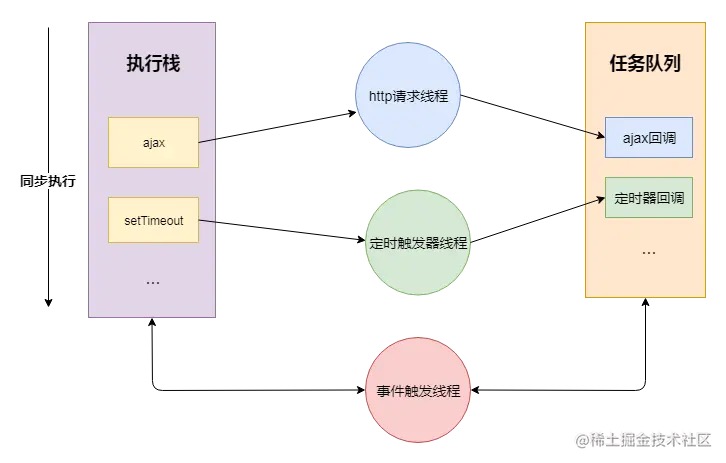
如何理解 JS 的运行机制(Event Loop)?
https://juejin.cn/post/6844903919789801486
核心概念
- JS分为同步任务和异步任务
- 同步任务都在
JS 引擎线程 上执行,形成一个执行栈
事件触发线程 管理一个任务队里,异步任务触发条件达成,将回调事件放入执行栈中执行- 执行栈中所有同步任务执行完毕,此时JS引擎线程空闲,系统会读取任务队列,将可运行的异步任务回调事件添加到执行栈中,开始执行
Event Loop
- 执行一个宏任务(栈中没有,就从任务队列中获取)
- 执行过程中如果遇到了微任务,就将它添加到微任务的任务队列中
- 宏任务执行完毕,立即执行微任务队列中的所有微任务(依次执行)
- 当前宏任务执行完毕,开始检查渲染,然后 GUI 渲染线程接管,开始渲染
- 渲染完毕后,JS 线程接管,开始下一个宏任务(从任务队列中获取)
var 和 let 的区别
- var 声明的变量,其作用域为当前函数、模块或全局;let 声明的变量,其作用域总是在当前的代码块,例如语句块。
- 在同一个代码块中,var可以多次声明变量名;let只能声明一次,覆盖一个已经声明的 let 变量会导致语法错误。
- 用户可以在声明语句之前使用 var 变量,其值是 undefined. 而 let 必须先声明后使用。
- 全局模块下,var 声明的变量作为global上的属性,let声明的变量则不是 global上的属性,而是作为全局模块中的标识符。
垃圾回收机制
- 引用计数:被引用,则计数+1,不再引用,计数减一。存在循环引用问题。
- 标记清除(常用):当变量进入到执行环境,则标记上已进入执行环境,当执行完成后,变量离开执行环境则标记已离开执行环境。
原型链 & 继承
每个构造函数都有一个原型对象(prototype),原型有一个属性(constructor)指回构造函数,而实例有一个内部指针(proto)指向原型。
原型链最顶端是 null
任何函数的默认原型都是一个Object的实例,这意味着这个实例有一个内部指针指向Object.prototype。
这也是为什么自定义类型能够继承包括toString()、valueOf()在内的所有默认方法的原因
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
function Person(params) {
console.log(params)
}
const p = new Person(1)
p.__proto__.constructor === Person >>> true
p.__proto__ === Person.prototype >>> true
p.__proto__.__proto__ === Object.prototype >>> true
p.__proto__.__proto__.constructor === Object >>> true
p.__proto__.__proto__.__proto__ === null
|
原型与继承的关系
原型与实例的关系可以通过两种方式来确定。
第一种方式是使用instanceof操作符,如果一个实例的原型链中出现过相应的构造函数,则instanceof返回true
1
2
3
4
5
6
7
8
9
10
11
12
13
| function instance_of(instance, obj) {
let prototype = Object.getPrototypeOf(instance)
while(true) {
if (prototype === null) return false
if (prototype === obj.prototype) {
return true
}
prototype = Object.getPrototypeOf(prototype)
}
}
|
第二种方式是使用isPrototypeOf()方法
1
| Object.prototype.isPrototypeOf(o)
|
原型链的问题
问题一:原型中包含的引用值会在所有实例间共享
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| function Super() {
this.colors = ['red', 'blue']
}
function Sub() {}
Sub.prototype = new Super()
const o1 = new Sub()
o1.colors.push('black')
const o2 = new Sub()
console.log(o2.colors)
|
问题二:子类型在实例化时不能给父类型的构造函数传参
盗用构造函数继承
为了解决原型包含引用值导致的继承问题
在子类构造函数中调用父类构造函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| function Super() {
this.colors = ['red', 'blue']
}
function Sub() {
Super.call(this)
}
const o1 = new Sub()
o1.colors.push('black')
const o2 = new Sub()
console.log(o2.colors)
|
也可以给父类传递参数
1
2
3
4
5
6
| function Sub() {
Super.call(this, 'Hello world')
this.age = 18
}
|
盗用构造函数也是有缺点的:
- 不是原型链继承,无法使用父类原型对象上的属性和方法。
- 父类上定义的所有属性和方法,都会被复制到子类实例上,如果属性和方法太多,占用内存就会较大。并且继承的目的是为了属性和方法的
复用,而且借用构造函数是将父类定义的方法和属性进行了复制。
组合继承(伪经典继承)
综合了原型链和借用构造函数
基本的思路是使用原型链继承原型上的属性和方法,而通过盗用构造函数继承实例属性。这样既可以把方法定义在原型上以实现重用,又可以让每个实例都有自己的属性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| function Person(name) {
this.name = name
this.colors = ['red', 'blue']
}
Person.prototype.sayName = function() {
console.log(this.name)
}
function User(name) {
Person.call(this, name)
this.age = 19
}
User.prototype = new Person()
const u = new User('xiaoming')
console.log(u.sayName())
|
组合继承弥补了原型链和盗用构造函数的不足,是JavaScript中使用最多的继承模式。而且组合继承也保留了 instanceof操作符 和 isPrototypeOf() 方法识别合成对象的能力。
1
2
3
4
5
6
|
console.log(u instanceof User)
console.log(u instanceof Person)
console.log(User.prototype.isPrototypeOf(u))
console.log(Person.prototype.isPrototypeOf(u))
|
原型式继承
创建一个临时构造函数,将传入的对象赋值给这个构造函数的原型,然后返回这个临时类型的一个实例
1
2
3
4
5
6
7
| function object(o) {
function F() {}
F.prototype = o
return new F()
}
|
ECMAScript 5通过增加Object.create()方法将原型式继承的概念规范化了。这个方法接收两个参数:作为新对象原型的对象,以及给新对象定义额外属性的对象(第二个可选: Object.defineProperties())。在只有一个参数时,Object.create()与这里的object()方法效果相同。
在 组合式继承中,我们可以将原型链继承那部分可以改写一下:
1
| User.prototype = Object.create(Person.prototype)
|
寄生式继承
创建一个实现继承的函数,以某种方式增强对象,然后返回这个对象
1
2
3
4
5
6
7
8
| function createAnother(original){
let clone = Object.create(original)
clone.sayHi = function() {
console.log("hi")
}
return clone
}
|
寄生式组合继承(继承的最佳模式)
组合继承其实也存在效率问题。最主要的效率问题就是父类构造函数始终会被调用两次:一次在是创建子类原型时调用,另一次是在子类构造函数中调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| function SuperType(name) {
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function() {
console.log(this.name);
};
function SubType(name, age){
SuperType.call(this, name);
this.age = age;
}
SubType.prototype=newSuperType();
SubType.prototype.constructor = SubType;
SubType.prototype.sayAge = function() {
console.log(this.age);
};
|
有两组name和colors属性:一组在实例上,另一组在SubType的原型上。
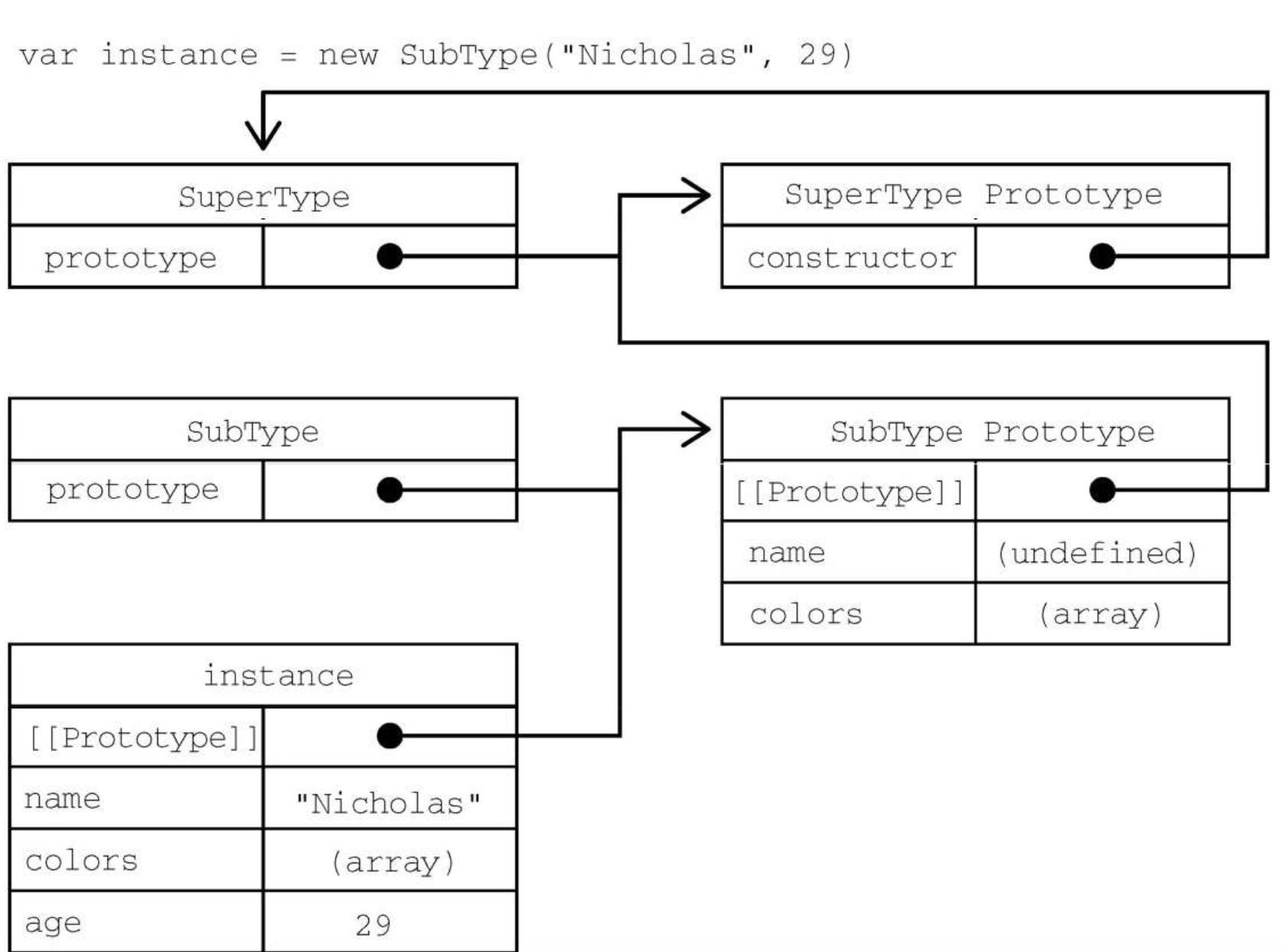
寄生式组合继承通过盗用构造函数继承属性,但使用混合式原型链继承方法。基本思路是不通过调用父类构造函数给子类原型赋值,而是取得父类原型的一个副本。
说到底就是使用寄生式继承来继承父类原型,然后将返回的新对象赋值给子类原型。
1
2
3
4
5
6
7
| function inheritPrototype(subType, superType) {
const prototype = Object.create(superType.prototype)
prototype.constructor = subType
subType.prototype = prototype
}
|
我们再来改写 组合继承
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| function SuperType(name) {
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function() {
console.log(this.name);
};
function SubType(name, age) {
SuperType.call(this, name);
this.age = age;
}
inheritPrototype(SubType, SuperType);
SubType.prototype.sayAge = function() {
console.log(this.age);
};
|
这里只调用了一次SuperType构造函数,避免了SubType.prototype上不必要也用不到的属性,因此可以说这个例子的效率更高。
而且,原型链仍然保持不变,因此instanceof操作符和isPrototypeOf()方法正常有效。寄生式组合继承可以算是引用类型继承的最佳模式。
ES6 class 的 extends 关键字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class Point {
constructor(x, y) {
this.x = x
this.y = y
}
}
class ColorPoint extends Point {
constructor(x, y, color) {
super(x, y)
this.color = color
}
}
|
子类必须在constructor方法中调用super方法,否则新建实例时会报错。这是因为子类没有自己的this对象,而是继承了父类的this对象,然后对其进行加工。如果不调用super方法,子类就得不到this对象。
如果在一个方法前加上static关键字,就表示该方法不会被实例继承,而是直接通过类调用,称为“静态方法”。
1
2
3
4
5
6
7
| class Foo {
static staticMethod() {
console.log('static')
}
}
Foo.staticMethod()
|
父类的静态方法可以被子类继承。
1
2
3
| class Bar extends Foo {}
Bar.staticMethod()
|
父类的静态方法可以在子类中通过 super 关键字调用。
1
2
3
4
5
6
7
| class Bar extends Foo {
static say() {
return super.staticMethod() + ' method'
}
}
Bar.say()
|
class 和构造函数有什么区别?
类必须使用new调用,直接调用会报错
类和模块的内部,默认就是严格模式,所以不需要使用use strict指定运行模式。
类不存在变量提升(hoist),这一点与 ES5 完全不同。
类的内部所有定义的方法,都是不可枚举的
子类必须在constructor方法中调用super方法,否则新建实例时会报错。
这是因为子类自己的this对象,必须先通过父类的构造函数完成塑造,得到与父类同样的实例属性和方法,然后再对其进行加工,加上子类自己的实例属性和方法。如果不调用super方法,子类就得不到this对象。
super作为函数调用时,代表父类的构造函数。
1
2
3
4
| <script>
class A {}
class B extends A { constructor() { super() }}
</script>
|
super虽然代表了父类A的构造函数,但是返回的是子类B的实例,即super内部的this指的是B的实例,因此super()在这里相当于A.prototype.constructor.call(this)。
继承区别
- ES5 的继承,实质是先创造子类的实例对象this,然后再将父类的方法添加到this上面 Parent.call(this)
- ES6 的继承机制,实质是先将父类实例对象的属性和方法加到this上面(所以必须先调用super方法),然后再用子类的构造函数修改this。
防抖&节流
防抖:用户触发事件频繁,只需要用户最后一次操作的结果
1
2
3
4
5
6
7
8
9
10
11
12
13
| const input = document.querySelector('input')
let timer = null
input.oninput = function(){
if (timer !== null) {
timer = clearTimeout(timer)
}
timer = setTimeout(() => {
console.log(this.value)
}, 1000)
}
|
封装防抖函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| function debounce(fn, delay = 500) {
let timer = null
return function() {
if (timer !== null) {
clearTimeout(timer)
}
timer = setTimeout(() => {
fn.call(this)
}, delay);
}
}
const input = document.querySelector('#input')
input.oninput = debounce(function() {
console.log('value: ', this.value)
}, 800)
|
节流:控制事件执行的次数,每个多少时间间隔执行一次。
比如监听滚动条的触发事件。
1
2
3
4
5
6
7
| let time = 0
window.onscroll = function() {
if (Date.now() - time > 1000) {
console.log('执行')
time = Date.now()
}
}
|
封装节流函数 throttle
1
2
3
4
5
6
7
8
9
10
11
| function throttle(fn, delay) {
let time = 0
return function() {
let now = Date.now()
if (now - time > delay) {
fn.call(this)
time = now
}
}
}
|
纯函数
- 函数的返回结果只依赖于它的参数,相同的输入始终得到相同的输出。
- 函数执行过程中没有副作用(不改变、不依赖外部任何可观察的变化)
1
2
3
4
5
6
|
function add(a, b) {
return a + b;
}
add(1, 2)
|
可缓存的纯函数
当我们的计算量非常大,可能耗时很长或者很好性能,那么我们通过缓存的方式,避免函数多次计算。从而,计算了一次之后,以后再输入相同的参数,就直接返回上次计算的结果。
lodash.memozie(add, resolver)
实现 memoize 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| function add(a, b) {
console.log('计算中...')
return a + b
}
const resolver = (...args) => JSON.stringify(args)
function memoize(func, resolver) {
const cache = {}
return function(...args) {
const key = resolver(...args)
if (cache[key]) {
return cache[key]
} else {
return cache[key] = func(...args)
}
}
}
const memoized = memoize(add, resolver)
console.log(memoized(9, 9))
console.log(memoized(9, 9))
console.log(memoized(9, 9))
|
函数柯里化
给一个函数传入一部分参数,让其返回的函数接收剩余的参数。直到所有的参数都给到了,才会计算结果。
lodash.curry(fn)
1
2
3
4
5
6
7
8
9
10
|
function add(a, b, c) {
return a + b + c
}
const fn = lodash.curry(add)
console.log(fn(1, 2, 3))
console.log(fn(1)(2, 3))
console.log(fn(1)(2)(3))
|
实现 curry 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| function curry(func) {
const curried = function(...args) {
if (args.length < func.length) {
return (...rest) => curried(...args, ...rest)
} else {
return func(...args)
}
}
return curried
}
function add(a, b, c) {
return a + b + c
}
const curried = curry(add)
const fn = curried(1)
console.log(fn(2)(3))
|
函数组合
看个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| const str = 'hello '
function add1(str) {
return str + 'wor'
}
function add2(str) {
return str + 'l'
}
function add3(str) {
return str + 'd'
}
console.log(add3(add2(add1(str))))
|
我们通过手动组合的方式,将每个函数的结果拼接了起来,能实现想要的结果,但是过于繁琐,假设还有几个函数或者十几个函数,恐怕写下去人都麻了。
好在 lodash 这个库也帮我们实现了这个方法 flow & flowRight
1
2
3
| const f = lodash.flow(add1, add2, add3)
f(str)
|
手动实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| const str = 'hello - '
function add1(str) {
return str + 'wor'
}
function add2(str) {
return str + 'l'
}
function add3(str) {
return str + 'd'
}
function flow(...fns) {
if (fns.length === 1) {
return fns[0]
}
return fns.reduceRight((a, b) => {
return (...args) => a(b(...args))
})
}
const f = flow(add1, add2, add3)
console.log(f(str))
|
跨域
什么是跨域?
CORS 全称是 Cross-Origin Resource Sharing,意为跨域资源共享。当一个资源去访问另一个不同域名或者不同端口的资源时,就会发出跨域请求。如果另一个资源不允许其进行跨域资源访问,就会造成跨域。
跨域不是问题,是浏览器的安全机制
跨域不会阻止请求的发出,也不会阻止请求的接收,跨域是浏览器为了保护当前页面,你的请求得到了响应,但是浏览器不会将请求到的数据提交给当前页面上的回调,取而代之的是去提示你这是一个跨域数据。
同源策略导致。
所谓同源策略,就是协议、域名、端口号都要相同,有一个不相同,那么就是非同源,就会出现跨域。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
http:
http:
https:
http:
https:
https:
http:
https:
|
解决跨域
- 纯后端方式
假设我们有个后端服务 3000,提供了 /user 接口,我们可以直接在 .html 文件中访问,如果后端不设置跨域,那么肯定会出现跨域提示的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
const express = require('express')
const app = express()
app.get('/user', (req, res) => {
res.json({
code: 0,
msg: '请求user成功'
})
})
app.listen('3000', () => {
console.log('server running at port 3000...')
})
<script>
const xhr = new XMLHttpRequest()
xhr.open('get', 'http://localhost:3000/user')
xhr.onload = function() {
consolelog(xhr.response)
}
xhr.send()
fetch('http://localhost:3000/user')
.then(res => res.text())
.then(res => {
console.log(res)
})
</script>
|
后端设置跨域访问
1
2
3
4
5
6
7
8
9
|
app.all('*', function(req, res, next) {
res.header("Access-Control-Allow-Origin", "*")
res.header("Access-Control-Allow-Headers", "*")
res.header("Access-Control-Allow-Methods", "*")
next()
})
|
- 前端处理
主要是通过 webpack devServer 的 proxy 来处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| ...
devServer: {
proxy: {
'/api': {
target: 'http://localhost:3000/'
}
},
proxy: {
'/no-api': {
target: 'http://localhost:3000/',
pathRewrite: {
'/no-api': '',
}
}
},
}
...
|
- Nginx
要注意的是,devServer 配置 proxy 只是存在于我们开发项目时有用,如果项目要上线,devServer 就没有了,这时可以考虑采用 Nginx 来代理。
- 前后端合并方式
我们可以不采用 devServer proxy 方式,而是在后端配置 webpack-dev-middleware,将前后端进行合并。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| const express = require('express')
const webpack = require('webpack')
const middle = require('webpack-dev-middleware')
const compile = require('./webpack.config.js')
const app = express()
app.use(middle(compile))
app.get('/user', (req, res) => {
res.json({
code: 0,
msg: '请求user成功'
})
})
app.listen('3000', () => {
console.log('server running at port 3000...')
})
|
- jsonp
比较老、兼容性好的方式。
利用标签没有跨域限制的漏洞,在 script 标签上我们可以引用其他服务上的脚本。
最常见的场景就是 CDN.
1
| <script src="https://cdn.jsdelivr.net/npm/vue@2.7.14/dist/vue.js"></script>
|
使用方式:
1
2
3
4
5
6
7
8
9
10
| function callback(res) {
console.log(JSON.stringify(res, null, 2))
}
const script = document.createElement('script')
script.src = 'http://127.0.0.1:3000/info/jsonp?cb=callback'
document.getElementByTagsName('head')[0].appendChild(script)
|
前端路由
模式有两种:
- hash 模式
- history 模式
URL 的 hash 也就是锚点(#),本质上是改变 window.location 的 href 属性。可以直接给 href 复制,但是页面不刷新。
1
2
3
| location.href
location.href = '/foo'
|
HTML5 新增。
它有五种模式改变 url 而不刷新页面。
1
2
3
4
5
6
| history.pushState({}, '', '/foo')
history.replaceState({}, '', '/foo')
history.go(-1)
history.back()
history.forward()
|
在 Vue 中,有两种方式可以跳转路由:
- 申明式路由
<router-link to="/go">跳转</router-link>
- 编程式路由
this.$router.go('/go')
实现 vue-router 路由
https://www.bilibili.com/video/BV1n24y1w7kP?p=25&spm_id_from=pageDriver&vd_source=a9f38e58a519cc0570c2dacd34ad7ebe
Promise
所谓Promise,就是一个对象,用来传递异步操作的消息。它代表了某个未来才会知道结果的事件(通常是一个异步操作),并且这个事件提供统一的API,可供进一步处理。
特点:
对象的状态不受外界影响(pedding, resolved, rejected)
一旦状态改变就不会再改变
1
2
3
4
5
6
7
| const p = new Promise((resolve, reject) => {
if (true) {
resolve(true)
} else {
reject(false)
}
})
|
resolve函数的作用是,将Promise对象的状态从“未完成”变为“成功”(即从Pending变为Resolved)
reject函数的作用是,将Promise对象的状态从“未完成”变为“失败”(即从Pending变为Rejected)
1
2
3
4
5
6
7
8
9
10
| function timeout(ms) {
return new Promise(resolve => {
setTimeout(resolve, ms, 'done')
})
}
timeout(1000).then(res => {
console.log(res)
})
|
resolve函数的参数除了正常的值外,还可能是另一个Promise实例,表示异步操作的结果有可能是一个值,也有可能是另一个异步操作:
p1的状态决定了p2的状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| const p1 = new Promise((r, reject) => {
setTimeout(() => {
reject(new Error('fail'))
}, 3000);
})
const p2 = new Promise((r, reject) => {
r(p1)
})
p2.then(result => {
console.log('result ', result)
}, error => {
console.log('error ', error)
})
|
上面的代码中,p1是一个Promise,3秒之后变为Rejected。p2的状态由p1决定,p2调用resolve方法,但是此时p1的状态还没有改变,因此p2的状态也不会变。等3秒过后,p1变为Rejected,p2也跟着变为Rejected。
需要注意的是,catch方法返回的还是一个Promise对象,因此后面还可以接着调用then方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| new Promise(r => {
r(x + 2)
}).then(res => {
console.log('结果 ', res)
}).catch(err => {
console.log('错误 ', err)
}).then(() => {
console.log('随便打印')
}).finally(() => {
console.log('最后打印')
})
错误 ReferenceError: x is not defined
随便打印
最后打印
|
Promise.all
Promise.all方法用于将多个Promise实例包装成一个新的Promise实例。
1
| const p = Promise.all([p1, p2, p3])
|
p的状态由p1、p2、p3决定,分成两种情况。
只有p1、p2、p3的状态都变成Fulfilled,p的状态才会变成Fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数。
只要p1、p2、p3中有一个被Rejected,p的状态就变成Rejected,此时第一个被Rejected的实例的返回值会传递给p的回调函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
| const p3 = function() {
return new Promise(r => {
setTimeout(() => {
r('p3 success')
}, 3000);
})
}
const allP = Promise.all([1, 2, p3()])
allP.then(r => {
console.log(r)
})
|
上面的例子,3秒后,输出 [ 1, 2, 'p3 success' ]
Promise.race
竞速
有一个实例率先改变状态,p的状态就跟着改变。那个率先改变的Promise实例的返回值,就传递给p的回调函数。
超时处理
1
2
3
4
5
6
7
8
| const p = Promise.race([
fetch('http://localhost:3000/api/user'),
new Promise((r, reject) => {
setTimeout(() => {
reject(new Error('Request timeout'))
}, 5000)
})
])
|
上面的代码中,如果5秒之内fetch方法无法返回结果,变量p的状态就会变为Rejected,从而触发catch方法指定的回调函数。
async await
async/await被称为Generator函数的语法糖,是因为它们之间具有一些相似的特性和作用。
使用Generator函数时,需要手动编写迭代器的控制逻辑,即不断调用next方法来推进函数的执行。而async函数则更加简洁,通过使用async关键字声明函数,并在函数内部使用await关键字来等待异步操作的完成。使用await关键字可以暂停函数的执行,等待Promise对象的解析,并将解析值作为结果返回。整个过程更加类似于同步代码的书写,避免了手动编写迭代器的繁琐操作。
从语法角度来看,async/await确实简化了异步编程的过程,使得代码更加易读和易于维护。它们隐藏了Generator函数的复杂性,并提供了更直观的方式来处理异步操作。因此,我们可以说async/await是Generator函数的一种更高级的语法糖形式。
async/await的内部原理是基于Generator函数来实现的。在JavaScript引擎内部,async函数会被转化为一个状态机,而await表达式会被转化为适当的yield表达式。
当遇到一个async函数时,JavaScript引擎会将其转化为一个返回Promise的普通函数。在函数内部,通过Generator函数的方式来实现异步操作的控制流。
我们来看一段 async/await 转为为 ES5 的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| async function async1 () {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2 () {
console.log('async2')
}
console.log('script start')
async1()
console.log('script end')
function async1() {
console.log('async1 start');
return async2().then(function() {
console.log('async1 end');
});
}
function async2() {
console.log('async2');
return Promise.resolve();
}
console.log('script start');
async1().then(function() {
console.log('script end');
});
|
async函数返回一个Promise对象,可以使用then方法添加回调函数
1
2
3
4
5
6
7
8
| async function sayName() {
return 'name'
}
console.log(sayName())
sayName().then(res => console.log(res))
|
当函数执行时,一旦遇到await就会先返回,等到触发的异步操作完成,再接着执行函数体内后面的语句。
我们来实现一个 sleep 睡眠函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
const sleep = function(ms) {
return new Promise(r => {
setTimeout(() => {
r()
}, ms);
})
}
async function sayName() {
console.log(1)
await sleep(3000)
console.log(2)
return 'name'
}
sayName().then(res => console.log(res))
|
当我们调用 sayName 方法时,会立即打印出 1, 3秒过后,打印 2 和 ’name‘
注意
await命令后面的Promise对象,运行结果可能是Rejected,所以最好把 await 命令放在try…catch代码块中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| const sleep = function(ms) {
return new Promise(r => {
console.log(xxxxx + 3)
setTimeout(() => {
r()
}, ms)
})
}
async function sayName() {
try {
await sleep(3000)
} catch (error) {
console.log(' - - - ', error)
}
}
sayName().then(res => console.log(res))
|
迭代器 Symbol.iterator
不改变等式代码,如何让下面这个等式成立?
let [a, b, c] = { a: 1, b: 2 }
对象是不具备 Symbol.iterator 迭代器工厂函数的,我们可以手动创建一个。
1
2
3
4
5
6
7
| Object.prototype[Symbol.iterator] = function () {
return Object.values(this)[Symbol.iterator]()
}
let [a, b, c] = { a: 1, b: 2 }
console.log('result ', a, b, c)
|
解构操作,调用迭代器方法。